
VidBot:让Stretch3机器人看视频就能学动作,零样本执行成现实
在机器人技术的发展历程中,如何让机器人高效学会执行各类复杂动作,一直是科研人员探索的关键课题。
近期,一项名为 VidBot 的技术“横空出世”,为该领域带来了突破性进展。它实现了机器人直接从视频学习生成执行动作,为机器人的智能化发展开辟了新路径。
引言:机器人如何像人类一样学习?
想象一下,如果机器人能够像人类一样通过观看视频学习新技能,那将是多么高效和便捷!
传统的机器人训练需要大量人工演示和编程,成本高且难以规模化。然而,慕尼黑工业大学、苏黎世联邦理工与微软的最新研究 VidBot 提出了一种创新方法:
机器人仅需观看人类日常视频,就能学会执行复杂的操作任务,无需人工训练或机器人专用演示。
传统困境与 VidBot 的创新突破
传统机器人学习执行动作的方式,往往依赖大量真实世界数据或仿真训练。收集这些数据不仅耗费大量人力、物力,而且针对不同硬件形态的机器人,还需单独进行训练,这无疑极大地限制了机器人技术的推广与应用。
VidBot 则另辟蹊径,它能从自然单目 RGB 人类视频中学习三维空间表征(3D affordance),构建起一个零样本机器人操作框架。
简单来说,就是机器人无需针对特定任务进行复杂的前期训练,就能依据视频中的人类动作,直接执行相应操作。其技术核心在于通过精妙的算法,从视频里提取出 3D 手部轨迹,再利用独特的学习模型,将这些轨迹转化为机器人可执行的动作指令。

VidBot的核心技术:从视频到机器人动作
1. 从2D视频提取3D动作
VidBot的核心创新在于从单目RGB视频中提取3D手部轨迹,并结合深度估计模型(如Depth Anything)和运动恢复结构(SfM)技术,重建出时序一致、度量尺度的三维空间表征(3D affordance)。
- 3D手部轨迹提取:VidBot利用SfM优化相机位姿,并结合手-物检测模型(如Segment Anything)分割手和物体,最终生成3D交互轨迹。
- Affordance学习:机器人不仅能识别“接触点”,还能预测“目标点”和完整的交互路径,例如“如何打开抽屉”或“如何拿起水壶”。

2. 从粗到细的动作生成
VidBot 采用“两阶段学习模型”:
- 粗预测(Coarse Prediction):识别接触点和目标点(如“抽屉把手”和“拉开方向”)。
- 细预测(Fine Prediction):利用扩散模型(Diffusion Model)生成平滑的3D轨迹,并结合测试时刻约束(如避障、多目标优化)确保动作合理。

实验结果:零样本泛化能力惊人!
VidBot在13个日常操作任务(如开橱柜、推抽屉、拿水壶)上进行了测试,成功率高达88.2%,远超现有方法(如VRB、GAPartNet)。在Hello Robot Stretch3(7DOF开源移动操作机器人)上,VidBot成功执行了推拉、抓取、开关等任务,成功率80%以上。

VidBot 的实际应用大放异彩
家庭服务领域
在家庭场景中,移动操作机器人的需求持续增长。Hello Robot Stretch3搭载VidBot技术后,能通过观看人类日常动作视频,快速模仿执行开橱柜、推抽屉等任务。例如在厨房场景中,它可精准识别目标位置,规划运动路径完成取物操作,为家庭生活增添便利。
教育科研场景
7DOF 开源移动操作机器人(如Stretch3)结合VidBot技术,能成为教育科研的得力工具。科研人员可通过视频让其掌握实验流程,学生则能直观观察机器人的学习过程,加深对编程与运动控制的理解,激发对机器人技术的探索兴趣。
结语与展望
VidBot的技术突破,让机器人通过视频学习技能成为可能,而Hello Robot Stretch3作为适配该技术的移动操作机器人,在家庭服务、教育科研等场景中展现出显著优势。

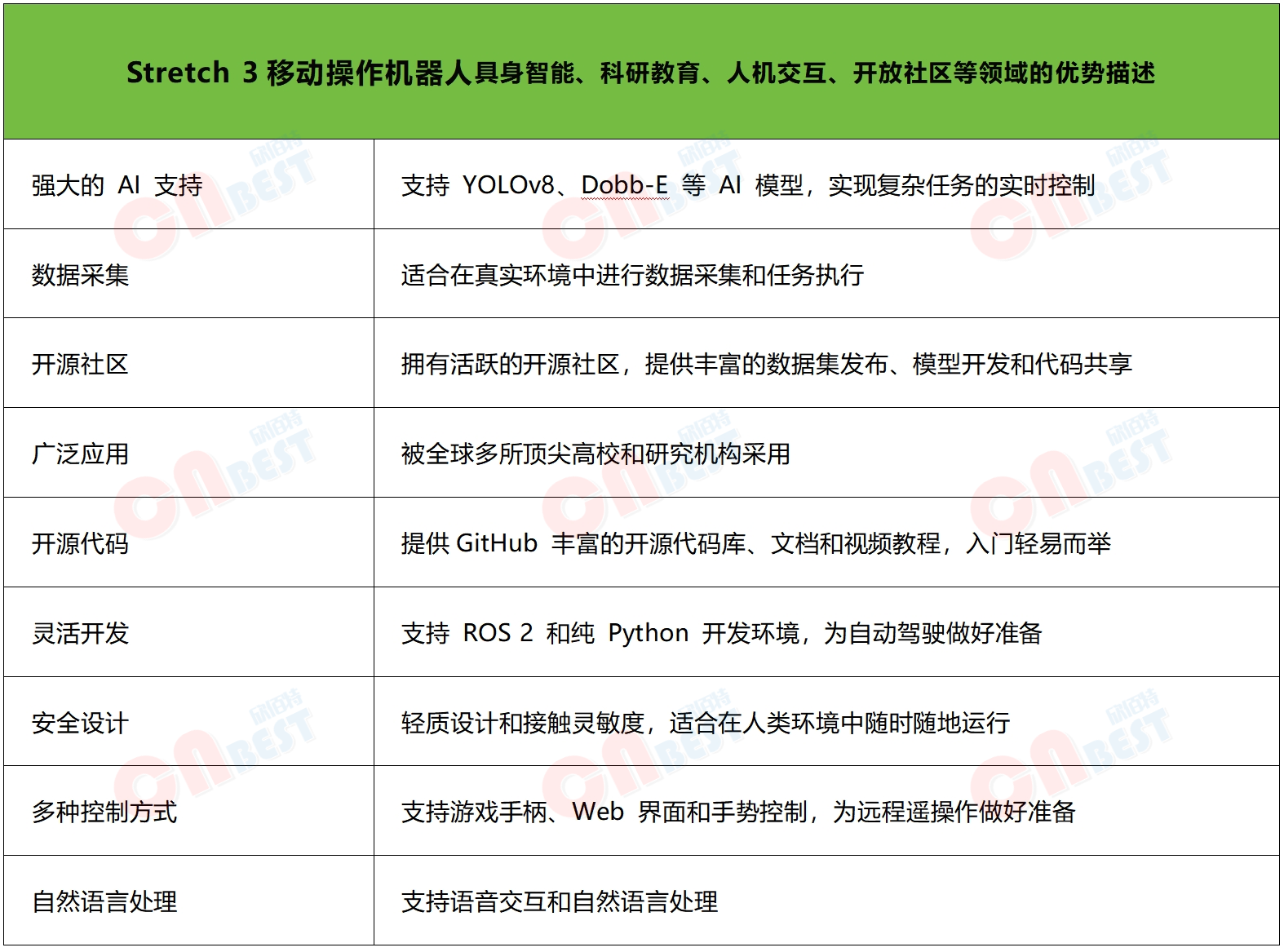
随着技术迭代和Hello Robot 移动操作机器人Stretch 3的广泛社区支持,在未来Stretch3有望更深度融入多元场景,为用户带来更智能的体验。

【版权声明】
本文部分技术内容及数据援引自论文《VidBot: Learning Generalizable 3D Actions from In-the-Wild 2D Human Videos for Zero-Shot Robotic Manipulation》(arXiv:2503.07135v2)。项目网站:https://hanzhic.github.io/vidbot-project/

